drugchecking
UNC Drug Checking Lab - Datasets
March 2023: This documentation is in beta release. Expect changes.
We are a public service of the University of North Carolina. Our mission is to provide the best data to prevent the most harm. For too long, people have only been told what’s in the drug supply when it is too late: Dead or arrested. We are changing that by making data public for harm reduction programs and the people they serve.
To make sense of complex chemical names, we deploy sophisticated natural language processing (NLP) and semi-automated chemical and statistical analysis to find patterns in street drug data. We strive to make sample results readable to humans. But we also make datasets with extensive pre-processing so you can get on with science.
We intend for our datasets to be used only in the service of preventing health harms. We reserve the right to hold accountable anyone who touches these data with other intents, including scheduling.
For the sake of data transparency, we expect attribution. We do not require authorship. (Though, collaboration is welcome.) We make all our code publicly available and expect you will do the same when using our data. We expect publications to be in open access journals, and plain language summaries provided back to the communities from which the samples arose. These are our community standards. We hope you will respect them.
Tyranny of the Molecule
Mary Figgatt and Nabarun Dasgupta pointed out, molecules alone cannot tell the complete story of the experience with any given sample. We do not believe in molecules explaining everything. That is why our datasets also include subjective information and overdose experiences. We expect all analyses with these data to honor this contributed wisdom.
As [drug checking] programs expand, we offer 2 guiding principles. First, the primary purpose of these programs is to deliver timely results to people who use drugs to mitigate health risks. Second, innovation is needed to go beyond criminal justice paradigms in laboratory analysis for a more nuanced understanding of health concerns.
Also check out our Canadian colleagues on how we ensure equitable access to drug checking and data.
Gratitude
Above all, we salute the front line harm reduction and public health workers who care for our communities. They are essential. Over years of shared trauma, they are the ones who have built trust in the communities they serve. Without their cooperation, none of this knowledge would be possible. We expect them to be hailed in the Acknowledgements section of any manuscript or publication that results from the use of our data.
Every chemical analysis was done by Erin Tracy, our lead chemist. We thank you for your service. Maryalice Nocera and Colin Miller keep the operation running, for which we are eternally grateful. Nabarun Dasgupta wrote the code, so mistakes can happen.
Warning
These data are intended for public health use to save lives.
These data cannot be used for criminal prosecution because they are completely anonymous and do not conform to legal chain of custody requirements. We explicitly prohibit the use of these data for drug scheduling purposes.
Data Privacy Statement
All samples were collected anonymously. No information identifying individuals or programs is available.
Resources available in human readable format for the general public, and in machine readable format for technical audiences.
General Public
- If you are ready to start drug checking by mail, request a startup kit.
- Sample collection tutorial video
- Browsable results (searchable)
- Google Sheets example data table viewer
Chemistry Audience
- Chemical Dictionary with pronunciations and classifications
Software Developers
- Confirmatory/complementary testing results are automatically uploaded to FTIR records using Street Check from Brandeis University
- Machine-oriented CSV access to results for confirmatory/complementary testing
- GitHub repo for data products
- Processing code showing variable creation
- NLP code for converting sample results into human readable individual records for website
- Canonical list of all completed sample ID
Epidemiology Audience
- [Full technical data details](https://github.com/opioiddatalab/drugchecking/blob/main/datasets/technical_details.md]
- Data collection card and sample collection instructions PDF
- Full documentation in codebook
- List of all samples containing xylazine
- All North Carolina samples in human readable format.
- North Carolina xylazine report live report web app with live updated data
- Methods text for grant proposals and papers.
File Inventory
analysis_datasetExample analysis dataset in WIDE format with processed and derived variables (N=20)
Stata
Excel
SAS
CSVlab_detailExample lab detail dataset in LONG format with standardized chemical names (N=20)
Stata
Excel
SAS
CSV
The sampleid variable links the datasets analysis_dataset.* and lab_detail.*.
For a quick view of the data, see this Google Sheets example as a single file with 2 tabs.
Analysis Dataset
The file analysis_dataset.* contains one row for each sample. It includes the characteristics that were reported on the card, and handy pre-processed variables to aid data analysis and visualization. The variable convention allows the analyst to quickly generate a time-series of how many samples contained fentanyl, for example.
It also contains 1/0 derived flags to help easily answer many common analytic questions, such as whether the sample contains xylazine, or if any fentanyl processing impurities (like 4-ANPP) were detected. These derived variables are indicated with the naming convention lab_ in the variable name. The presence of particular compounds is marked _any in the variable name to indicate that the substance was detected in primary or trace amounts. The lack of a _any in the variable name means that it was the detected as a primary substance. Therefore, this sample contains xylazine in trace abundance lab_xylazine_any=1 but not as a primary constituent lab_xylazine=0.
| sampleid | date collected | lab_fentanyl | lab_fentanyl_impurity | lab_xylazine | lab_xylazine_any |
|---|---|---|---|---|---|
| 123 | 12dec2022 | 1 | 1 | 0 | 1 |
You can import the example analysis_dataset.csv instantly into Google sheets by pasting this one line of code into the first cell (A1):
=importData("https://raw.githubusercontent.com/opioiddatalab/drugchecking/main/datasets/analysis_dataset.csv")
Lab Detail Dataset
The lab_detail.* file contains one row for each substance detected for each sample. The derived variables use the same naming convention and allow for understanding how each substance is classified. Additional variables can be constructed using searches on the substance variable. This file does not contain the information from the card provided during sample collection, which instead appears in analysis_dataset.* for the sake of data efficiency. This also allows you to see trace back and see how variable was constructed at an individual chemical level.
| sampleid | substance | method | abundance | lab_fentanyl | lab_fentanyl_impurity | lab_xylazine | lab_xylazine_any |
|---|---|---|---|---|---|---|---|
| 123 | fentanyl | GCMS | 1 | 0 | 0 | 0 | |
| 123 | xylazine | GCMS | trace | 0 | 0 | 0 | 1 |
| 123 | 4-ANPP | GCMS | 0 | 1 | 0 | 0 |
You can import the example lab_detail.csv instantly into Google sheets by pasting this one line of code into the first cell (A1):
=importData("https://raw.githubusercontent.com/opioiddatalab/drugchecking/main/datasets/lab_detail.csv")
See full technical data details for more info
GCMS Chromatograms
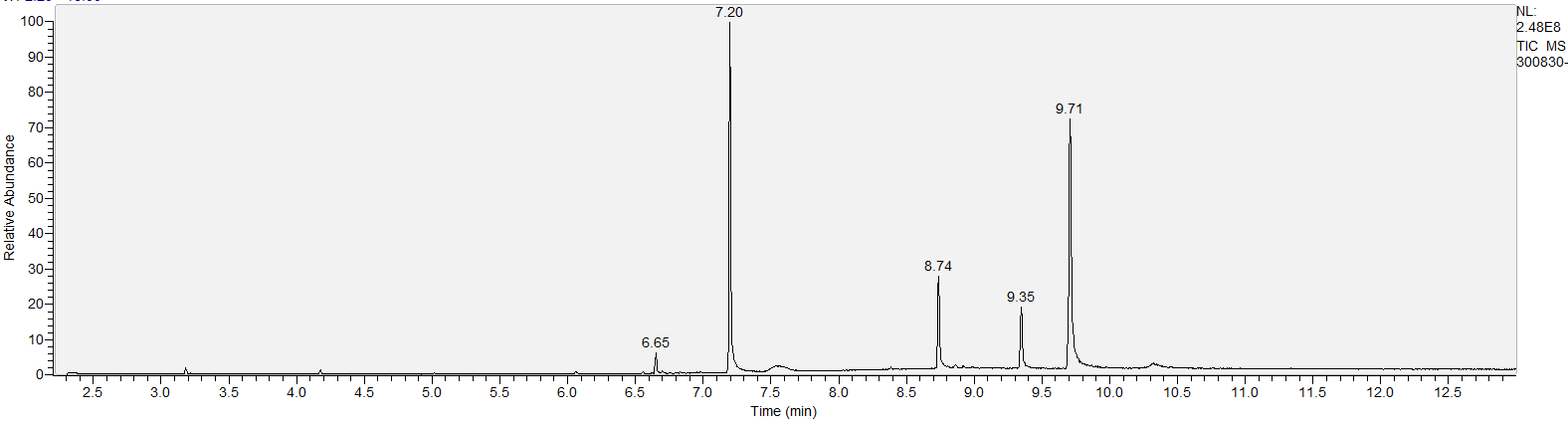
The chromatogram is one of the outputs we analyze, a summary of the constituents (note: the chromatogram above is similar to, but not exactly the same, as the structured data example). All chromatograms can be found in this folder in PNG format. File naming convention is just the sample ID followed by .PNG. Syntax for direct call for spectra image files via URL:
https://raw.githubusercontent.com/opioiddatalab/drugchecking/main/spectra/300830.PNG
Peaks are labeled in the human readable record, which can be searched here.
Major substances in graph:
- Peak 6.65 = caffeine
- Peak 7.2 = xylazine
- Peak 8.74 = 4-ANPP
- Peak 9.35 = heroin
- Peak 9.71 = fentanyl
fin.